Pagination with GraphQL
Pagination is a very important part of modern user interfaces. It's important to consider pagination for performance reasons if working with larger data sets.
There are multiple ways of implementing pagination, and this documentation highlights some approaches and how they can be implemented in GraphQL.
Pagination basics
This approach is based on the following resources:
- https://graphql.org/learn/pagination/
- https://slack.engineering/evolving-api-pagination-at-slack-1c1f644f8e12
- https://api.slack.com/docs/pagination
- https://simonkollross.de/posts/implementing-cursor-based-pagination-in-laravel
- https://www.sitepoint.com/paginating-real-time-data-cursor-based-pagination/
However, it more closely follows the approach taken by Slack. The official GraphQL documentation shows a very sophisticated example using edges and nodes, which we have deliberately not implemented. In most of our scenarios this complexity is not needed.
In web development, two main types of pagination are common:
- Offset-based pagination
- Cursor-based pagination
Offset-based pagination
This type is well known and the most widely used. One example in Totara is the pagination of reports:

The dataset is divided into pages, limited by the maximum number of items per page (which can be configured in the report settings).
If we know the page number (page) we want to load, the maximum number of items per page (limit), and the total number of results (total), we can automatically determine the rest and display a section like the example above.
Usually given the page number and the total number of results, we use offset and limit in our database query to get the desired results.
This works well for a relatively static dataset which does not change very often. We can even use it to display a Load more button, which triggers the next page (the next set of items) to be loaded.
The problems arise when your dataset changes while you are browsing it.
The article https://www.sitepoint.com/paginating-real-time-data-cursor-based-pagination/ describes the problem very well. Here is the relevant excerpt:
Assume that we have 20 records initially and we using 10 as the limit to break the records into pages. The following image shows how records are broken into pages.

Now assume that the result set is updated by five new records while we are on the first page. The following image shows the current scenario.
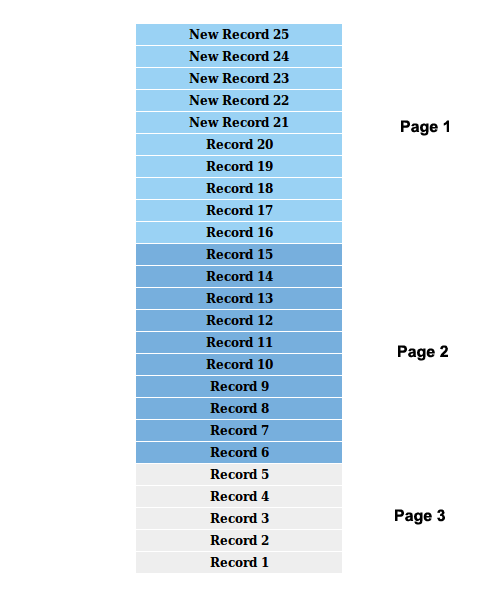
Now we navigate to the second page. Based on our first image, it should retrieve the records from 1-10. However, records with numbers 15-6 will be retrieved. You can clearly see that record numbers 15-11 are displayed in both the first page as well as the second page.
Compared to that, cursor-based pagination offers a solution to this problem.
Cursor-based pagination
In cursor-based pagination, the result contains a pointer to a specific item in the dataset. On the next request, the server returns the next set of items coming after that cursor. This approach does not have the concept of pages like the offset-based approach.
This addresses the problem outlined above, but has the following trade-offs:
- A total number of results is not as valuable, as the number can change between requests
- You cannot jump to a specific page
- The cursor must be based on a unique, sequential column (or combination of columns)
This approach is best suited for the Load more approach or infinite scrolling through a list. The pagination we use in our report builder wouldn't be possible with this approach.
Cursor basics
A cursor acts as a pointer to a specific item in the result-set. It's a piece of data which identifies the location of the item in the list.
It has the following requirements:
- Uniqueness
- Sequential
Usually our IDs in the database table fit those requirements, but your result-set might not always be ordered by the ID. Therefore the cursor can point to a combination of columns which fulfil the above outlined requirements.
We use opaque cursors.
Why use an opaque cursor?
In principle a cursor can be a single value, such as a creation date or multiple values, like an array of columns. Using a value directly does impose a meaning and would change from query to query. But we want the cursor to be a cursor (or a pointer) and nothing more, and every query should be able to use the same interface.
To support this, we convert the actual value of the cursor into a base64 encoded string. That makes it opaque. It helps in reminding the client to not rely on the cursor value to be of any particular type or have any particular meaning other than being a marker to identify the last item in the returned page.
This allows us to technically implement different underlying pagination schemes per query, while providing a consistent interface to the consumers of the query.
With an opaque cursor we can cover both the offset-based and the cursor-based pagination.
Example
Here's an example of how a query structure supporting both methods of pagination would look.
The query should be sorted by the creation timestamp, and should return an array of items containing the unique ID, the name and the creation timestamp.
The first query will send null as the cursor, thus relying on the defaults defined in the back end to determine how many items per page are returned.
The client can then use the next_cursor returned in the result for the cursor sent in the next request.
Sorting
It is important to ensure that the results are sorted in a consistent way across requests. If the first column alone does not guarantee a unique sorting then we need to include at least a second column to sort by. In this example, the created_at is not unique. If two entries have the same creation timestamp, including the id as a second column will ensure consistent results.
Query
query my_pageable_query (
$cursor: String
) {
pageable_query (
cursor: $cursor
) {
items {
id
name
created_at
}
next_cursor
}
}
Cursor (offset-based)
If an offset-based cursor is used, the cursor is a JSON- and base64-encoded form of:
{
page: 1
limit: 20
}
Cursor (column-based)
If a column-based cursor is used, the cursor is a JSON- and base64-encoded form of:
{
limit: 20
columns: {
created_at: 1586403210
id: 125
}
}
Example response
{
"data": {
"pageable_query": {
"items": [
{
"id": 1,
"name": "Fritz",
"created_at": 1586403200
},
{
"id": 3,
"name": "Morgan",
"created_at": 1586403205
},
{
"id": 7,
"name": "Greta",
"created_at": 1586403110
},
{
"id": 8,
"name": "Donald",
"created_at": 1586403110
},
],
"next_cursor": "eyJsaW1pdCI6MjAsImNvbHVtbnMiOnsiY3JlYXRlZF9hdCI6MTU4NjQwMzExMCwiaWQiOjh9fQ=="
}
}
}
next_cursor
In a cursor-based pagination the next_cursor value can be used to load the next set of items.
In an offset-based pagination, if the Load more approach is used, the next_cursor can also be used directly to load the next page. In other cases which do support navigating to specific pages, the value of the next_cursor has to be set and encoded by the client, as it depends on the action of the user (e.g. clicking on a specific page, previous or next, etc.).
Total
The total amount of items should be an optional field in the response. In some cases it makes sense to return this value, while in other cases it doesn't. In a rapidly changing dataset the total number returned would vary per request, and it also has a performance impact on the query. In a more static dataset, returning the value would help to reduce the number of requests to get the same information.
End of results
How do we know when we have reached the last page? In this case the backend should return "" (an empty string) as the next_cursor.
Interface
Implementing a core interface ensures that all queries returning paginated results follow the same structure.
interface core_pageable_result {
total: Int
next_cursor: String
}